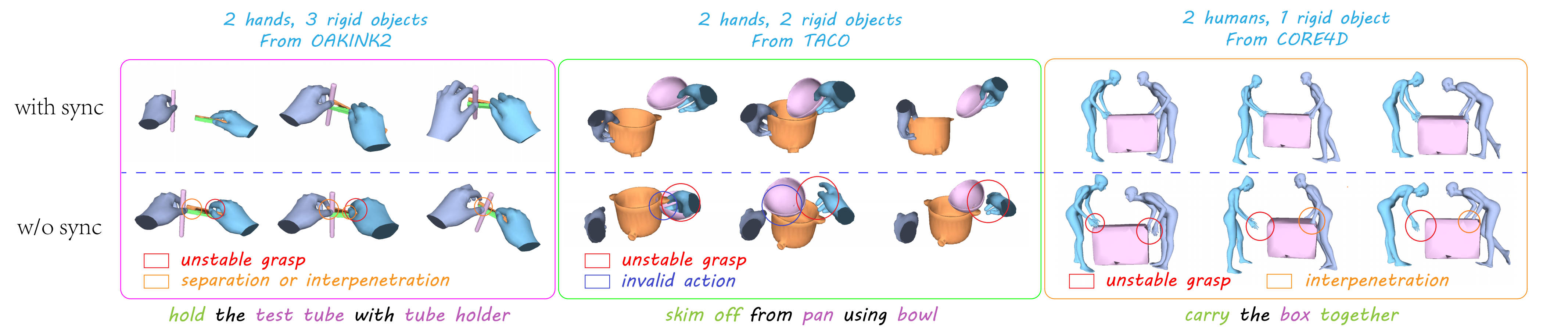
SyncDiff is a unified framework synthesizing synchronized multi-body interaction motions with any number of hands, humans, and rigid objects. In SyncDiff, we introduce two novel multi-body motion synchronization mechanisms, namely the alignment scores for training and explicit synchronization strategy in inference. With these mechanisms, the synthesized results can effectively prevent interpenetration, contact loss, or asynchronous human-object interactions in various scenarios, as shown in the above figure.